







首先,C4.5是决策树算法的一种。决策树算法作为一种分类算法,目标就是将具有p维特征的n个样本分到c个类别中去。相当于做一个投影,c=f(n),将样本经过一种变换赋予一种类别标签。决策树为了达到这一目的,可以把分类的过程表示成一棵树,每次通过选择一个特征pi来进行分叉。
那么怎样选择分叉的特征呢?每一次分叉选择哪个特征对样本进行划分可以最快最准确的对样本分类呢?不同的决策树算法有着不同的特征选择方案。ID3用信息增益,C4.5用信息增益率,CART用gini系数。
下面主要针对C4.5算法,我们用一个例子来计算一下。
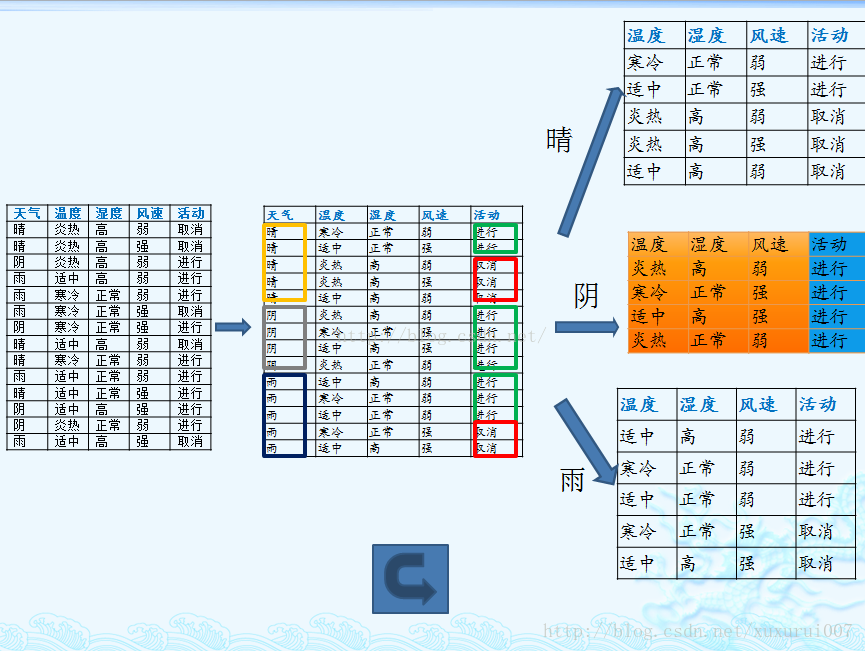
上述数据集有四个属性,属性集合A={ 天气,温度,湿度,风速}, 类别标签有两个,类别集合L={进行,取消}。
1. 计算类别信息熵
类别信息熵表示的是所有样本中各种类别出现的不确定性之和。根据熵的概念,熵越大,不确定性就越大,把事情搞清楚所需要的信息量就越多。

2. 计算每个属性的信息熵
每个属性的信息熵相当于一种条件熵。他表示的是在某种属性的条件下,各种类别出现的不确定性之和。属性的信息熵越大,表示这个属性中拥有的样本类别越不“纯”。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









